Speech-to-world is a Generative AI (GenAI)-based application to create and edit VR environments. As part of a 6-month work in 2024 I was charged with building a World Generator using generative AI. The idea is to create a VR application where the user can simply say want it wants to see, and let the AI generate the environment. It can then edit the environment to add elements or remove details. The result of this work can be seen at HugoFara/speech-to-world-server and HugoFara/speech-to-world-unity-client.
The process has a few independent steps. For a complete explanation the source of truth is the GitHub wiki.
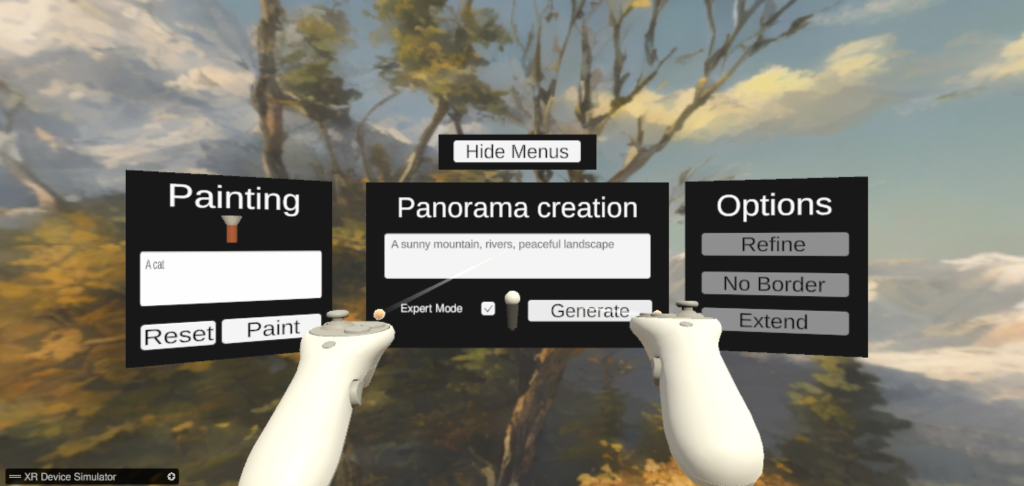
The technical demo for Speech-to-World
VR application
First off, the user interacts with a VR application built with Unity and OpenXR. The idea is mostly to present a limited number of 3D panels with options to avoid overloading the user with too many choices.
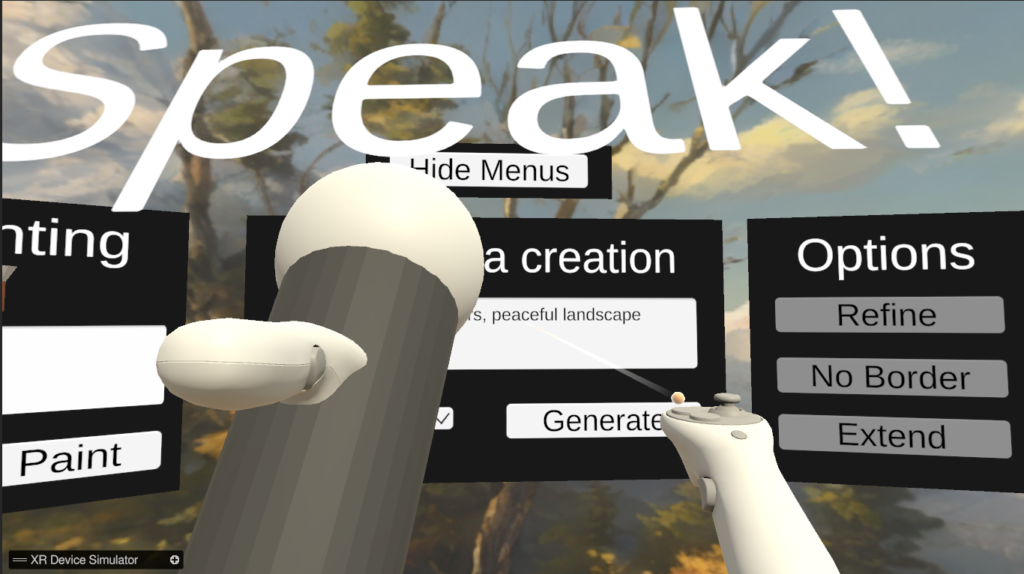 An illustration of the activated microphone
An illustration of the activated microphone
In particular, there is a microphone object that can be grabbed and activated. Once activated, the user can speak inside to record their voice, while an Automatic Speech Recognition (ASR or speech-to-text) model transcripts and translates everything in English.
For records, the ASR and translation models are both Whisper-v3.
Skybox generation
The skybox generation is the most important feature of this project. It is a heavily modified text-to-image model with the following characteristics:
- There is no horizontal border. Placing the image side-by-side would give an asymmetric horizontal tiling.
- The two poles (top and bottom) are modified to avoid any visible deformation (known as the hairy ball theorem).
I used several models but stuck with a combination of Stable Diffusion XL 1.0 and Stable Diffusion XL 1.0 Inpainting 0.1 for their great consistency with each other.
Once both constraints are satisfied, we effectively get a text-to-skybox model, which is very good at rendering landscapes. Yet, we want a 3D map, which needs quite some more work.
Depth generation
A progressive approach to 3D models is to use an image-to-depth model. These models will create a “surface” of our environment that we can extend for a real 3D scene. The best model at the time was Marigold.
 An AI-generated landscape image
An AI-generated landscape image  A depth coloration using Marigold
A depth coloration using Marigold
On the left is the depiction of an original AI-generated image (using SD XL 1.0 base only). On the right is the heatmap of the generated depth for the same image.
As we can see it has a high fidelity to details.
Image segmentation
We have an RGBD image, but we are unable to say what are the elements belonging to the skybox, the terrain or the 3D objects. To solve it we will use a segmentation model. We will use the following classification rules:
- Remote elements (for instance depth > 80 % max depth) belong to the skybox
- The ground has a depth that monotonously increases on vertical lines from bottom to top. In other words, the sign of its vertical gradient is fixed.
- Whatever remain are 3D elements.
These rules proved to be robust enough to be used, with better results than ML and AI based segmentation methods.
Segments completion
We are basically cutting parts from an original image, resulting in incomplete elements. We have to complete them.
Skybox
For this segment we use a first ML-based inpainting. I used biharmonic inpainting to stick with skimage, but Navier-Stokes based inpainting (TELEA), may be better for users of OpenCV.
Terrain
For the terrain, we first need to complete the depth map. It is a multi-step process that involves “brushing” the depth map to reduce noise, before computing the gradient and removing the elements with null gradient. Then, a depth-based ControlNet is used to rebuild the terrain.
Once all segments are completed, we have at least two images: the skybox and the RGBD terrain. The objects are in a separate category.
Terrain generation
Now, we want to use our RGBD terrain segment to get a real terrain. A terrain is an RGBH (H for height) image. The idea is mainly to use a projection to get a top-view of the image, which leaves new holes. These holes need to be inpainted.
3D elements
For the 3D elements, image-to-3D models can be used with our completed object segments. The problem here was that I did not find any good open-source model back in mid-2024, which left the task uncompleted.
Conclusion
We have a full-framework for speech-to-environment using only open-source models and standard technologies. It is aimed at being highly reusable and customizable, so I hope you will enjoy it. Don’t hesitate to leave a star, an issue, or a comment so that I know what I should do next!